
HTTP/2 en el mundo real
El nuevo protocolo de red HTTP/2 continúa implementándose con fuerza en la web. Sergio Sánchez, Programmer Analyst de Ipglobal, profundiza con el siguiente artículo en las claves, fundamentos y ventajas de este protocolo frente a su predecesor.
Para poder contaros qué es el nuevo protocolo HTTP/2 y por qué se supone que va a cambiar el mundo web, tenemos que empezar por el principio. ¿Qué significa eso de HTTP? Según la definición de la Wikipedia HTTP (Hypertext Transfer Protocol) o protocolo de transferencia de hipertexto, es el protocolo de comunicación que permite la transferencia de información en la World Wide Web. Desde su nacimiento en el año 1991 este protocolo define la sintaxis y semántica que utilizan los elementos de software de la arquitectura web (clientes, servidores, proxies) para comunicarse. La versión más extendida es la 1.1, que vio la luz en el año 1999 y que permite el uso de los métodos GET, POST, PUT, DELETE, etc. En resumen: el protocolo HTTP no es más que un grupo de métodos, reglas y especificaciones que permite que los ordenadores transmitan información.
HTTP/2 es la última versión del protocolo HTTP. Llega con el objetivo de mejorar las carencias existentes de las versiones anteriores.
- HTTP/2: Ventajas respecto a HTTP/1.1
HTTP/2 se basa en el protocolo SPDY, presentado en 2009 por Google. Por aquel entonces SPDY prometía un aumento de entre el 30 y 60% de velocidad de carga para las webs.
- Formato binario: en HTTP/1.1 las cabeceras viajaban en formato texto, con HTTP/2 las cabeceras viajan en formato binario. Esto hace que sean más fáciles de analizar, más compactas y mucho menos propensas a errores.
- Multiplexed Streams: Con HTTP/1.X ocurre un problema llamado “Head-of-line blocking”, donde una congestión puede ocurrir cuando solo se usa una solicitud por conexión. La multiplexación permite que el servidor pueda atender varias peticiones al mismo tiempo. Esto permite que la comunicación sea óptima ya que el cliente (el navegador) solo necesita establecer una conexión para cargar la página.
- Cabeceras comprimidas: compresión de las cabeceras mediante HPACK, un algoritmo específicamente diseñado para HTTP/2. Gracias a esto se consigue una mejora en la rapidez de las comunicaciones.
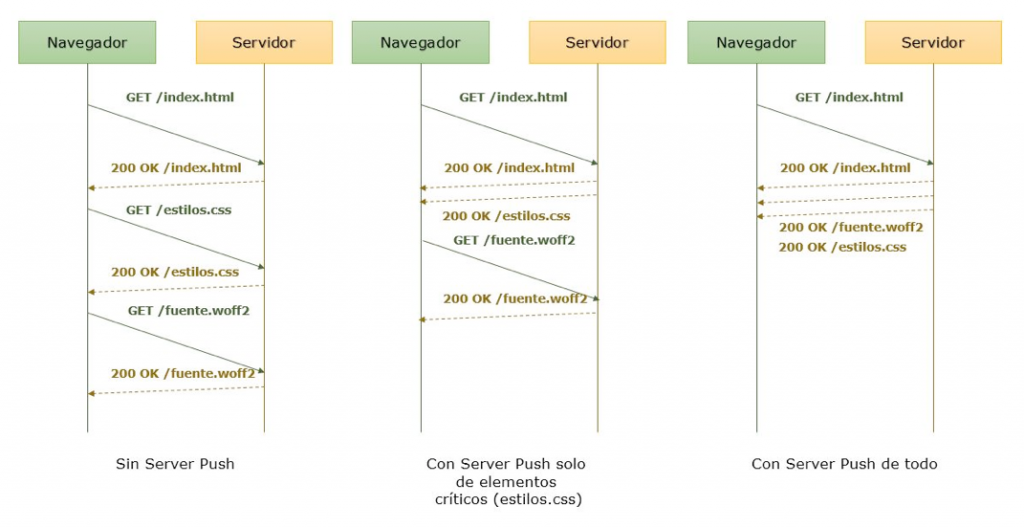
- Server Push: Esta es una de las características más interesantes del nuevo protocolo HTTP/2, permite que el servidor envíe recursos como imágenes, js, css, etc. al navegador sin tener que esperar a que el navegador los pida explícitamente.
Esta característica es sumamente útil. Con el protocolo HTTP/1.X tenemos que esperar a que el navegador analice el fichero html y descubra aquellos enlaces antes de que esos recursos puedan ser enviados. Esto ocasiona que la información viaje dos veces antes de que los datos lleguen al navegador (1 vez para obtener el html, y 1 vez para obtener ese recurso). Con Server Push podemos eliminar ese viaje extra y hacer que nuestro sitio web cargue más rápido.
Al menos en teoría, en un mundo ideal con ancho de banda ilimitado, podríamos enviar todos los recursos que nuestro fichero html necesita para renderizarse correctamente con la primera petición, eliminando completamente el tiempo de espera de los navegadores. Lamentablemente, en el mundo real el ancho de banda es muy limitado (conexiones WIFI, 4G, EDGE, ADSL…), con lo que enviar mediante Server Push algunos recursos de más, puede hacer que nuestro sitio empeore drásticamente la velocidad de carga.
2. Fundamentos y principios básicos
El rendimiento de HTTP/2 push depende mucho más de los protocolos de las subcapas de red y otros aspectos que del protocolo HTTP/2 en sí mismo.
Ancho de banda y TCP slow-start
En Internet, el ancho de banda disponible varía según el dispositivo y el tipo de red al que estemos conectados. Si tratamos de enviar muchos datos al mismo tiempo sobre una red muy congestionada, la propia red empezará a descartar el exceso de datos para evitar que se congestione totalmente y que se produzca el efecto llamado Packet Loss, o pérdida de paquetes.
Para que esto no ocurra, el protocolo TCP utiliza un mecanismo denominado slow-start. Su funcionamiento es sencillo, al principio empezamos enviando muy pocos datos, y solo vamos incrementando esta tasa de envío si la red lo puede aguantar (y de esta manera evitamos que se pierdan paquetes por el camino). En la práctica, el congestion window (un factor que determina el número máximo de bytes que deben enviarse cada vez, garantizando que no se congestione la red) es de 14kB en la mayoría de servidores Linux. Solo cuando el navegador confirma que ha recibido esos 14kB iniciales de forma satisfactoria (mediante un mensaje respuesta ACK), el servidor doblará esos 14kB de datos hasta los 28kB para enviar más datos cada vez. Después de la siguiente confirmación, el servidor volverá a doblar esa cantidad y así sucesivamente.
En el mundo real, esto significa que en una primera conexión nuestro servidor solo podrá enviar 14kB de datos al navegador en su primer viaje. Si enviamos más, serán encolados en el servidor hasta que el navegador confirme que ha recibido satisfactoriamente esos primeros 14 kB. En ese caso, el método Server Push no tiene beneficios adiciones: las peticiones tendrán que hacer dos o más viajes para completar la descarga completa del recurso. En una conexión ya establecida previamente, donde esa congestion window ya haya crecido en tamaño máximo de datos por viaje, podríamos enviar más cantidad datos en el mismo viaje sin que al final nos penalice en el rendimiento.
Y esto presenta un problema, ya que HTTP/2 utiliza solo un canal de conexión frente a los 6 canales paralelos que normalmente utiliza la implementación HTTP/1.1.
Prioridades
Como ya hemos dicho, HTTP/2 solo utiliza una única conexión TCP para el envío de datos. Para poder decidir qué datos deben ser enviados primero (cuando tenemos muchos recursos pendientes de enviar mediante Server Push), HTTP/2 emplea algo llamado prioridades. A cada recurso se le da un orden en el que tiene que (o mejor dicho, debe) ser enviado: el más importante y que primero tiene que enviarse es el html, así que tiene prioridad de 1, css y js tienen prioridad de 2 y 3, mientras que las imágenes tienen 4.
Si tenemos pendiente el envío de muchos recursos con la misma prioridad, los datos de estos recursos pueden ser enviarse intercalados: el servidor puede enviar pedazos de cada uno de esos ficheros en cada turno de envío. Este intercalado puede hacer que ambos recursos se retrasen, y pueden tardar mucho más en ser descargados totalmente. Esto puede funcionar bien si lo que se entrega son recursos como jpgs progresivos o html, pero posiblemente tenga un efecto negativo en recursos que necesitan ser completamente descargados para ser usados (como css o js).
Buffers
En la práctica existen muchos niveles de buffer: routers, torres de comunicación, sistema operativo, red… Puede llegar a pasar que HTTP/2 no pueda manejar correctamente las prioridades de los recursos a la hora de enviarlos al navegador. Puede ocurrir, por ejemplo, que mientras el navegador está recibiendo recursos del servidor vía Server Push, el propio navegador detecte que también necesita estilos.css y lo pida al servidor como un recurso prioritario. La situación ideal es que este fichero se envíe por delante te todos los no prioritarios que hay en cola, pero en la realidad ocurrirá que este fichero con prioridad 1, quede encolado hasta que no se sirvan el resto de recursos que estaban pendientes en la primera conexión.
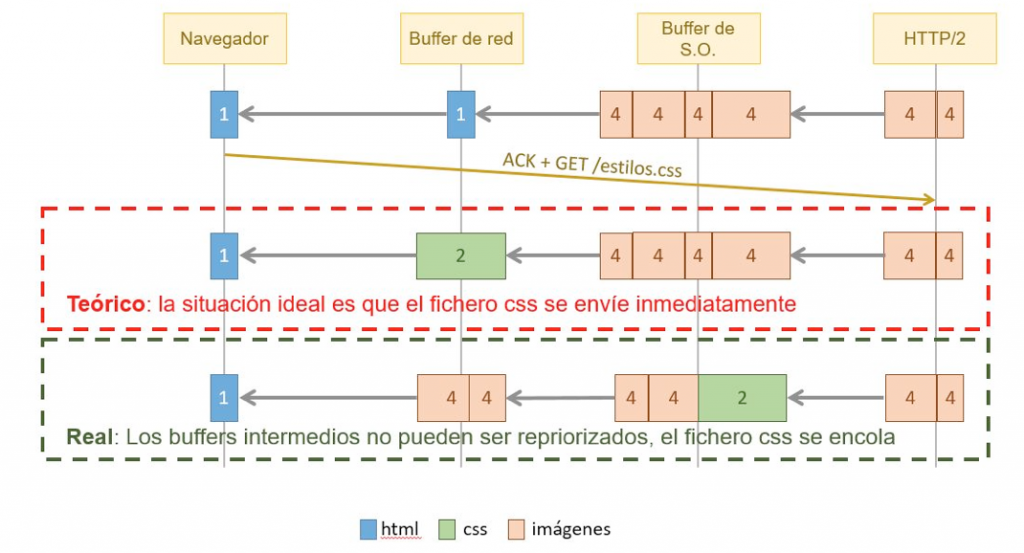
Esto puede solucionarse conociendo exactamente el orden (independientemente de su prioridad) en el que los recursos deben enviarse desde el servidor, evitando que los recursos prioritarios queden atascados.
Cachés
La mayoría de navegadores modernos y servidores CDN hacen uso de cachés para no tener el problema de tener que pedir constantemente el mismo recurso al servidor de origen, lo que ocasionaría problemas de ancho de banda y retrasaría la descarga de otros recursos que no han sido cacheados. El problema es que la especificación HTTP/2 todavía no recoge como debe ser implementada esta capa de caché, de forma que los recursos que enviamos vía Server Push se envían sin tener en cuenta ningún tipo de caché, lo que a la larga puede hacer que el rendimiento de nuestro sitio empeore.
3. Implicaciones prácticas. ¿Cuándo hacer Server Push?
Dependiendo del fin último se pueden visualizar 4 grandes posibilidades, cada una de las cuales tienen sus puntos negativos:
- Después del HTML: directamente después de enviar el HTML.
- Antes del HTML: antes/durante el navegador está esperando por el HTML (esta aproximación puede perjudicar el rendimiento si el recurso no está correctamente priorizado).
- Con un recurso: junto a otro recursos (puede no ser óptimo pero más fácil de priorizar/ordenar correctamente).
- De forma interactiva: después de que la página se cargue completamente (esta aproximación no mejora las métricas de velocidad de carga).
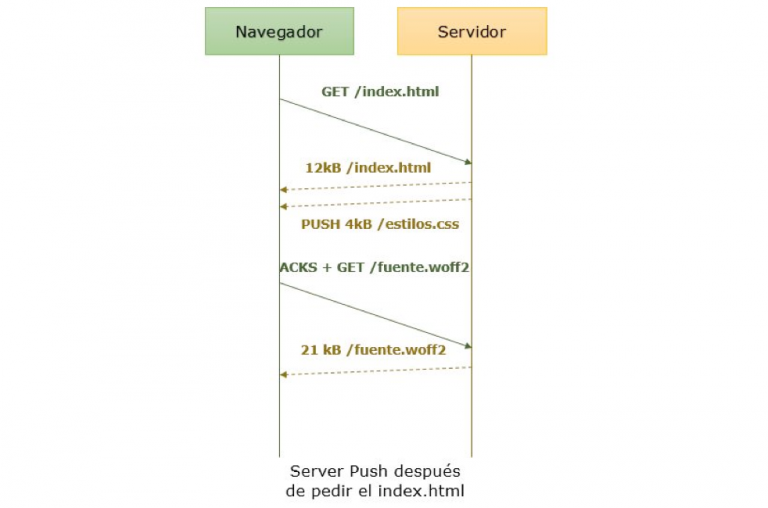
Después del HTML
Parece que la aproximación de enviar los recursos después del HTML es en lo que la mayoría de la gente piensa cuando se habla de Server Push, cuando es discutiblemente lo menos útil de la lista, especialmente cuando se trata de la primera conexión (ya hemos hablado del TCP slow-start).
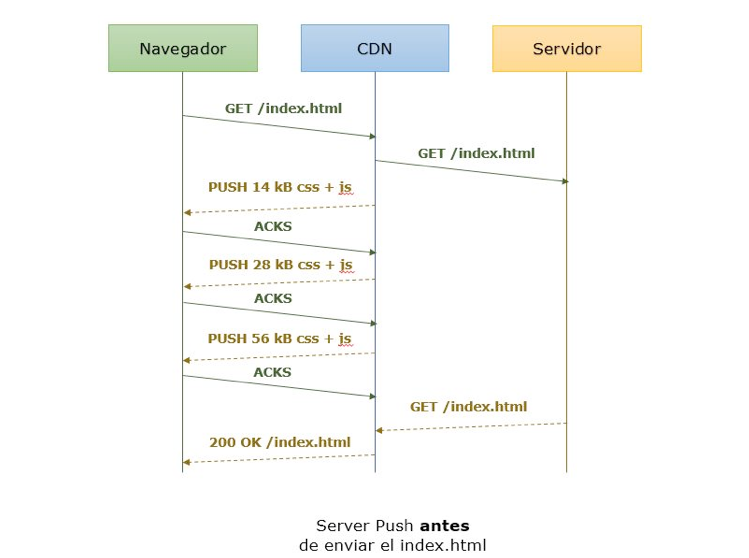
Antes/Durante el envío del HTML
Sin embargo, usar la aproximación de enviar los recursos antes/durante el HTML es más interesante: podemos incrementar la congestion window por adelantado, de modo que incluso respuestas html pesadas se pueden enviar en un solo viaje cuando estén disponibles.
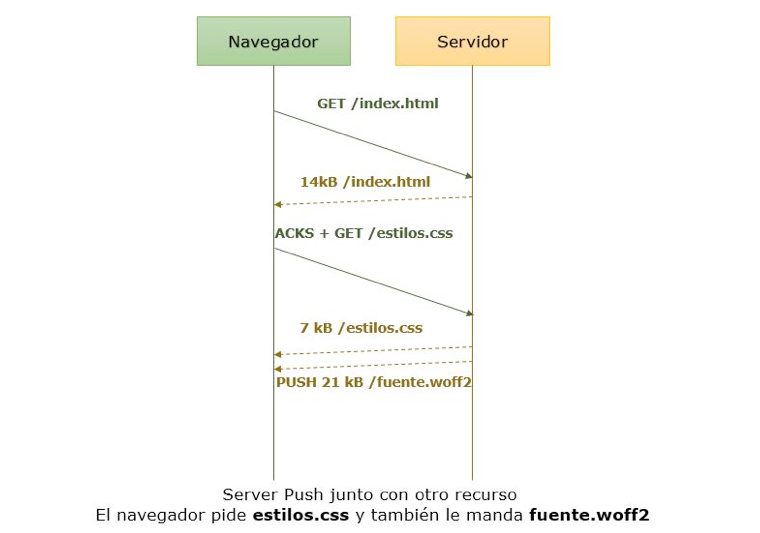
Junto con un recurso
La aproximación de enviar el Push junto a otro recurso puede ser menos óptima para mejorar la primera carga, pero seguro será mucho más fácil de manejar qué si la enviamos con el Server Push. Además, evitamos correr el riesgo de retrasar otros recursos. Por ejemplo, si dentro de un .css hacemos uso de un recurso tipo fuente externo que luego el navegador tendrá que solicitar, podemos hacer Server Push de esa fuente cuando el navegador solicite la descarga del fichero css.
De forma interactiva
Esta aproximación suele ser la más ignorada y la que más controversia genera por algunos porque parece haber un competidor directo más atractivo: Resource Hints (lo que comúnmente conocemos por <link rel=”preload/prefetch”>). Usar los Resource Hints puede hacer que el navegador pida un recurso antes de que lo necesite, tanto para la página actual como para las páginas sucesivas.
¿Qué recursos enviar mediante Server Push?
Como ya hemos visto, enviar recursos mediante Server Push puede retrasar la carga inicial si enviamos demasiado o en el orden incorrecto. Para hacerlo bien, necesitamos una vista completa en detalle del orden en el que los recursos deben ser cargados sin que esto repercuta negativamente en la velocidad de renderizado de nuestra web.
Problemas de usar Server Push en producción
A día de hoy las prioridades son muy inconsistentes:
- HTTP/2 espera que el cliente especifique la prioridad de los recursos en la petición, mientras que los servidores están permitidos a adherirse a esa prioridad o no.
- Firefox usa un tipo de aproximación por árbol de dependencia de varios niveles, mientras que Chrome solo usa un nivel de profundidad.
- A día de hoy no existe una manera de definir prioridades personalizadas (algo como <img src=”img.jpg” priority=”2” />) y es algo que actualmente ni siquiera está recibiendo propuestas concretas sobre cómo debe hacerse.
La implementación del lado del servidor no es clara
- Algunos frameworks (como nodejs) permiten acceder directamente (de forma programática) al Server Push vía API.
- La mayoría de servidores web lanzan el Server Push cuando reciben una cabecera con Link: <recurso.ext>; rel=preload; desde el backend (por ejemplo en PHP). Este es exactamente la misma cabecera que ahora deberíamos usar para precargar los Resource Hints, lo cual acaba confundiendo a los usuarios pero a la vez consigue un buen efecto colateral: aunque el servidor no respete el comando Server Push, el navegador igualmente precargará el recurso indicado en la cabecera.
Los navegadores o bien no están de acuerdo con la especificación, o bien no la implementan totalmente.
Nginx no soporta oficialmente Server Push y no parece tener planes de cambiar de parecer.
Apache implementa su propio módulo HTTP/2 son Server Push, pero avisa de que es un módulo experimental altamente inestable y que no debe usarse en producción.
Cloudflare ha creado su propio módulo de Server Push para Nginx y ya lo ofrece a sus clientes.
Akamai implementa su propia versión de Server Push.
La directiva PUSH_PROMISE no puede ser cancelada por el servidor.
Los recursos enviados mediante Server Push no son usados por el navegador de forma automática. El navegador todavía necesita pedir el recurso para ser evaluado y ejecutado.
4.Conclusiones
Si has llegado hasta aquí quizás opines lo mismo que yo: todavía es demasiado pronto para poner HTTP/2 Server Push en servidores de producción. Implementar Server Push en nuestros servidores no es algo que pueda hacerse a la ligera, requiere de una planificación exhaustiva donde se identifiquen los recursos críticos y se defina el orden correcto en el que deben enviarse al navegador.
Todavía estamos en una fase de maduración, tratando de comprender cómo funcionan estas nuevas tecnologías. Esto no quiere decir que HTTP/2 no tenga suficiente potencial, pero necesitamos más tiempo para descubrir cuál es la mejor implementación para nuestras webs. ¿Cuántos años llevamos tratando de optimizar HTTP/1.1? Pues con HTTP/2 pasará lo mismo, creo que esta tecnología todavía debe madurar antes de poder usarla en el grueso de las webs de internet.
Hay muchas cosas que todavía podemos mejorar usando el viejo protocolo HTTP/1.1: lazy loading de las imágenes y demás recursos que no sean necesarios para la primera visualización de la web, unificación y minificación de js y css, mejora de la respuesta del servidor (cachés intermedias, CDNs…), etc.
5. Fuentes
- https://es.wikipedia.org/wiki/Hypertext_Transfer_Protocol
- https://es.wikipedia.org/wiki/HTTP/2
- http://es.engadget.com/2015/03/06/que-es-http2-como-funciona/
- https://somostechies.com/que-es-http2
- https://http2.github.io
- https://speakerdeck.com/mgooding1981/velocity-santa-clara-h2-in-the-real-world
- https://docs.google.com/document/d/1K0NykTXBbbbTlv60t5MyJvXjqKGsCVNYHyLEXIxYMv0/edit
- https://blogs.akamai.com/2016/04/http2-enables-more-intelligent-resource-loading-via-stream-dependencies-but-its-not-as-simple-as-you.html
- https://www.nginx.com/blog/http2-r7/#comment-2302625444
- https://nghttp2.org/blog/2014/11/16/visualization-of-http-slash-2-priority/
- https://nghttp2.org/blog/2014/04/27/how-dependency-based-prioritization-works/
- https://calendar.perfplanet.com/2016/http2-push-the-details/
- https://atscaleconference.com/videos/http2-server-push-lower-latencies-around-the-world/
- http://cdn.oreillystatic.com/en/assets/1/event/167/The%20promise%20of%20Push%20Presentation.pdf